BEJOCAMA - Category Theory and C++
Table of Contents
- 1. Intro
- 2. Avoiding Loops
- 3. Functions as Interpretations
- 4. Functor in Category Theory
- 5. Function Application
- 6. Operators
- gate.io
- 8. Data as Interpretations
- 9. Typelist
- 10. Sidestep Logic
- 11. Polymorphic Types – Sumtype
- 12. Data as a Functor?
- 13. The Monad
- 14. The Monad Code
- 15. Currying
- 16. Applicative
- 17. Code Examples
- 18. Mathematics vs. Programming
- 19. References
\(\newcommand\identity{1\kern-0.25em\text{l}}\)
1. Intro
A programming language consists on a bunch of elements - variables, functions, objects, structures - which behave like it is defined by this language. But there is perhaps a motivation to work with self defined elements, which behaves in a certain way. We can talk about constructing a domain specific language or constructing a theory, which needs to be proved.
It's difficult to argue, that there is a need of a new language, because there are not so much people, who solved the same complex programming problem in two different languages and finally he came to the result, that the first one was more suitable than the second one.
Most programmers are interested in structural problems - but most programmers must also produce solutions for existing problems. So an interesting task could be, to move step by step to more powerful working - directly usable - concepts.
So I want to use existing features of a programming lanuguage and give them an appropriate meaning. In constrast to object oriented programming, where the Liskov principle is most important - a circle is a shape - I want to give things an interpretation, which may vary from context to context. So a circle can be interpreted as a shape, but other interpretations are also possible.
Such considerations lead to a very different programming style and new constructions to work with.
Sure, this approach is motivated by category theory. There, some authors are fascinated about functions. But is this fascination justified? Let's see if it slops over. Because programming is totally constructive, all ideas should here be representable by constructions - by code examples. Perhaps new for most interested readers is the interpretation aspect in contrast to an object oriented point of view.
For this I'm using C++ to express some ideas. The result is not a C++ programm - even if it seems to be. The most important feature of C++ I'm using is the template system, which allows generic programming. This is the connection to category theory, which has a generic nature.
Let's start to find out, if a new language can avoid loops. Because loops are connected to container data, a loop is a way to deal with container data.
2. Avoiding Loops
Why loops are a problem? Loops are a problem because of the body, which may contain portential programming errors. But if we consequently replace the loop body by a separated body function (perhaps a lambda), the problem is still in that function and the code may become perhaps worse to read
std::list<int> test_function(std::list<int> l) { std::list<int> rl; for(auto& e: l) { rl.emplace_back(e*e); } }
can be transformed to
std::list<double> test_function(std::list<int> l) { std::list<double> rl; auto one_third = [&rl] (int e) { rl.emplace_back(e*0.33333); }; for(auto& e: l) { one_third(e); } return rl; }
In the c++ standard we will find functional structures for avoiding explicitely looping
std::list<double> test_function(std::list<int> l) { std::list<double> rl; auto one_third = [&rl] (int e) { rl.emplace_back(e*0.33333); }; std::for_each(l.cbegin(), l.cend(), one_third); return rl; }
After a look on the code, can I deliver an argument, why we should do this? My answer is - at the moment it makes no sense. Because I want create a new language and we need some words of this language to construct something we can compare with the old language. This is an journey of construction experiments. So proclaiming a problem avoiding loops is at first a pseudo motivation and finally an introduction drug.
Let's now go a different direction and let's look on the functor concept
namespace cat { template<typename T> struct functor; template<typename T> struct functor<std::list<T>> { template<typename F, typename A> decltype(auto) operator()(F&& f, const std::list<A>& l) { using type = decltype(fwd(f)(std::declval<A>())); std::list<type> rl; auto x = [&rl,ff=fwd(f)](const auto& e) { rl.emplace_back(ff(e)); }; std::for_each(l.cbegin(), l.cend(), x); return rl; } }; }
The template functor is said here to be an interpretation and especially in this case an interpretation of a list. The macro fwd helps to shorten forwardings in the area of universal references. For the moment lets state
An interpretaton is a mapping of a type to another interpretation type.
Next take a look on the code
std::list<double> test_list_functor(std::list<int> l) { auto one_third = [] (int e) { return e*0.33333; }; return cat::functor<decltype(l)>()(one_third,l); }
The functor selector decltype(l) is not a perfect selector, because l stands for a value category - const or reference. Later we define an additional helper cleartype.
It's perhaps clear, that such container iterations can be generalized, so that the loop we only need to implement at one place.
But this is not enough. Important seems to me, to express the relation to an arithmetic calculation by an operator. First take a look on the wish
std::list<double> test_list_functor(std::list<int> l) { auto one_third = [] (int e) { return e*0.33333; }; return one_third <fa> l; }
In functional languages we can find a \(\lt{}$\gt{}\) operator. In c++ our possiblities to define operators are limited. I'm trying to circumvent this by using an approach found on different sites in the web, looking for "custom operators in c++". But what would the \(\lt{}a\gt{}\) operator express - in contrast to \(\lt{}fa\gt{}\) - simply
std::list<double> test_function(int i) { auto one_third = [] (int e) { return e*0.33333; }; return one_third <a> i; }
So
\(one\_third \lt{}a\gt{} i\)
is simply
\(one\_third(i)\).
Using an operator instead of parenthesis is a very important method to express value application in functional languages. So let's apply the function one_third two times, using the application operator
std::list<double> test_function(int i) { auto one_third = [] (int e) { return e*0.33333; }; return one_third <a> one_third <a> i; }
This looks much more elegent and readable than
std::list<double> test_function(int i) { auto one_third = [] (int e) { return e*0.33333; }; return one_third(one_third(i)); }
I think functional programmers wouldn't like so much these languages without having these operators.
We can see, that the operator \(\lt{}fa\gt{}\) is an extension of an ordinary function application, where the function is applied to a functorial value. And functorial means, that for a given value type exists a functor interpretation.
If we would generate a new function via the functor operator instead of directly applying the function to the value, we would get the following situation
std::list<double> test_list_functor(std::list<int> l) { auto one_third = [] (int e) { return e*0.33333; }; return cat::functor<decltype(l)>()(one_third) <a> l; }
We can directly apply the value to the new generated function. This approach of the functor implementation looks like
namespace cat { template<typename T> struct functor<std::list<T>> { template<typename F> constexpr decltype(auto) operator()(F&& f) { return [ff=fwd(f)] (auto&& l) { using type = decltype(ff(std::declval<decltype(*l.begin())>())); std::list<type> rl; for(auto& e: l) { rl.emplace_back(ff <a> e); } return rl; }; } }; }
Function generation code can always declared as constexpr. Perhaps it is surprising - because of the auto in the lambda declaration - it is possible to do the following
std::list<double> test_function(std::list<int> l) { auto one_third = [] (int e) { return e*0.33333; }; auto list_one_third = cat::functor<std::list<int>>()(one_third); return list_one_third <a> l; }
Because the lambda is a shortcut to an object with one call operator, the object list_one_third represents the object, not the operator function. The template resolution is done only at application time. Instead of using a lambda, we can make it more explicit, using a fun object
namespace cat { template<typename...> struct fun; template<typename T, typename F> struct fun<std::list<T>,F> { template<typename A> decltype(auto) operator()(A&& a) { using type = decltype(f(std::declval<decltype(*a.begin())>())); std::list<type> rl; for(auto& e: fwd(a)) { rl.emplace_back(f <a> e); } return rl; } F f; }; template<typename T> struct functor<std::list<T>> { template<typename F> constexpr decltype(auto) operator()(F&& f) const { return fun<std::list<T>,F>{fwd(f)}; } }; }
The fun interpretation or longer function is another interpretation, which is more fundamental then the functor interpretation. The next section will take a closer look on functions.
3. Functions as Interpretations
A functor interprets a templated type - a function introduced in this section will interpret types.
namespace cat { template<typename...> struct fun; }
To specify a function we must introduce a name as a type
namespace cat::name { struct sum; }
Now we can give the term sum an interpretation
namespace cat { template<> struct fun<name::sum> { template<typename A> A operator()(A&& x, A&& y) { return fwd(x) + fwd(y); } }; }
In this context name introduction is perhaps the better term than type forwarding. As a name a type is fully specified.
This interpretation of a function is closely related to a lambda, which isn't different from such a function with one call operator. Our function definition is more flexible, because we can build polymorphic functions
namespace cat { template<> struct fun<name::perimeter> { double operator()(const circle& c) { return 2 * pi * c.r; } double operator()(const rectangle& r) { return 2 * (r.a + r.b); } }; }
We need these functions to introduce the next language element - the polimorphic data type. This is done in one of the following sections.
Let's use the fun concept to introduce a lambda using a deduction guide
namespace cat { namespace name { struct lambda {}; } template<typename F> struct fun<name::lambda,F> { fun(F&& f, name::lambda) : m_f(fwd(f)) {} F m_f; }; template<typename F> fun(F&&) -> fun<name::lambda,F>; }
Now we can write
auto f = fun{[](){}};
If it is really a good idea, we will see later. For the moment I want to provide a helper operator - the plus sign, to make the lambda transformation easier
namespace cat { template<typename F> decltype(auto) operator+(F&& f) { return fun(fwd(f)); } }
Another thing we can do with a function, we can look on a functor as a special function
namespace cat { namespace name { struct functor; } template<typename T> struct fun<name::functor,T>; template<typename T> using functor = fun<name::functor,T>; }
At this ponit we can also make the code more general, if we look on a function as special obect
namespace cat { namespace name { struct function; } template<typename... T> struct cat; template<typename... T> using fun = cat<name::function,T...>; }
Perhaps we do such things to be able to make a difference between functions and objects
namespace cat { namespace name { struct object; } template<typename... T> using object = cat<object,T...>;
So it looks like a category, where we have objects and morphisms - arrows between objects - in our considerations - functions. But we have also situations, where in category theory objects themselves can be functions. It seems, that some or many mathematicians try to rid of the term object and try to regard only functions. They try to look on objects as a function representation.
4. Functor in Category Theory
The whole theory on avoiding loops can be express in an abstract diagram
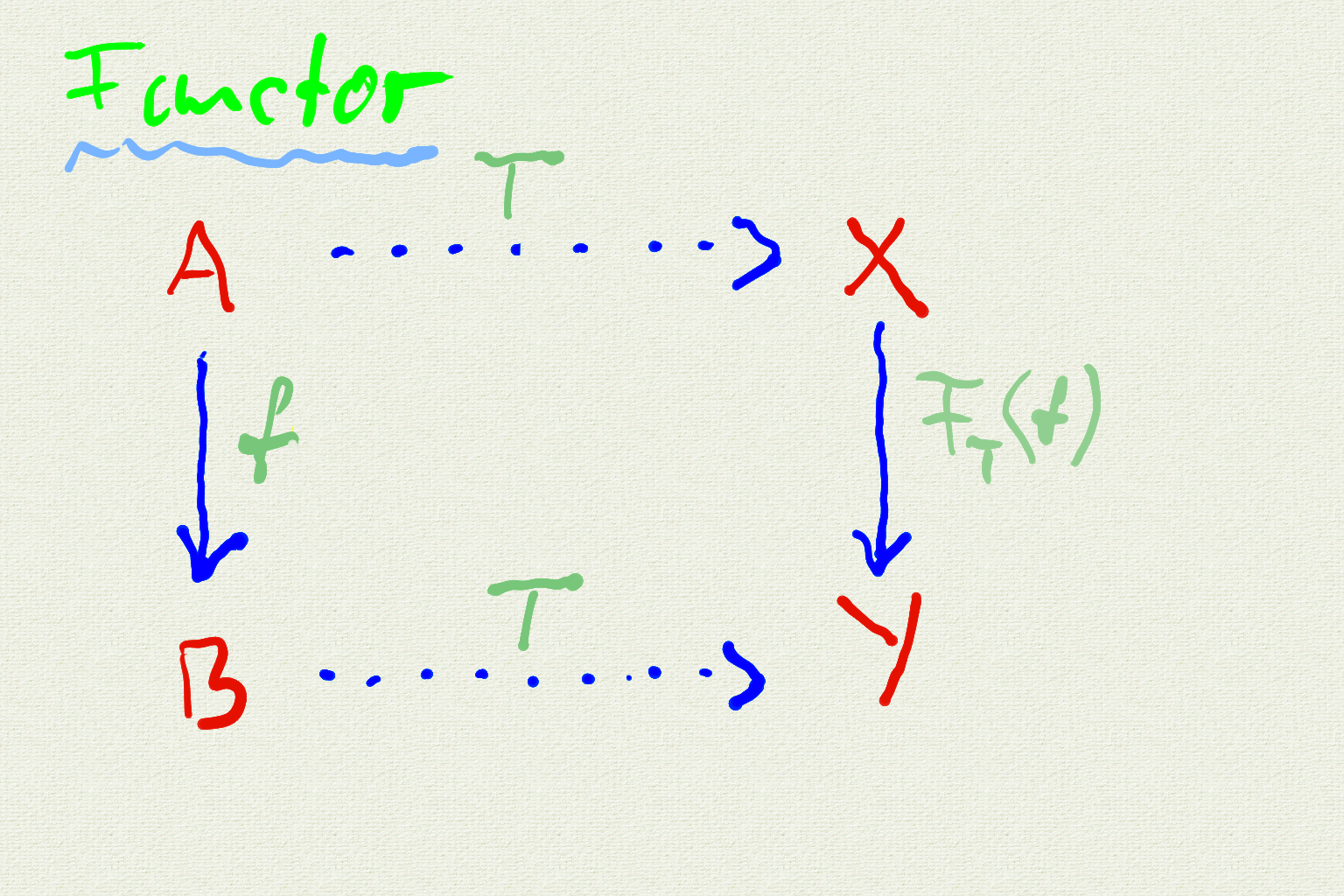
The meaning of the different arrow types is - they cannot be composed. The function f transforms a value of type A to a value of type B. The type transformation T maps a type value A to the type value X and the type value B to the type value Y. If we use value declarations, f can be defined as
\(f: (x:X) \rightarrow (y:Y)\)
and the type mapping T we can define as
\(T: (A:Type) \rightarrow (X:Type)\)
In our template language c++ we may write
\(X = T\langle{}A\rangle\)
But a language like Idris, where types are first class objects, we can write down this relation as a normal function
\(X = T(A)\)
An alternative way to describe a function is an exponential style
\(f: B^A\)
The superscript A denotes the type of the function argument - B represents the return type of the function.
This is what we have in the functor picture \(F_T(f)\), that is
\(F_T: B^A \rightarrow T\langle{}B\rangle{}^{T\langle{}A\rangle{}}\)
5. Function Application
Every binary function
\(f: A \otimes B \rightarrow C\)
can be expressed by two unary function calls
\(f(a,b) = \overline{f}(a)(b)\)
Here is \(\overline{f}\) the exponential transpose
\(\overline{f}: A \rightarrow C^B\)
With an application \($\) operator we can also write
\(f \ $\ (a,b) = \overline{f} \ $\ a \ $\ b\)
But what happens if we try to extrapolate this situation to an unary function
\(f \ $\ a = (\overline{f} \ $\ a)()\)
The exponential transpose takes a parameter and returns a function, which needs no argument to be executed. We can say
\(\overline{f} \ $\ a = \hat{f}_{f(a)} \qquad with \qquad \hat{f}_{f(a)}() = f(a)\)
In books on category theory the relation between a binary function and its exponential transpose is expressed by an evaluation function
\(eval: C^B \otimes B \rightarrow C\)
with
\(f = eval \cdot (\overline{f},\identity{})\)
We can now apply on both sides a value \((a,b):A \otimes B\)
\(f(a,b) = eval \cdot (\overline{f},\identity{})(a,b) = eval(\overline{f}(a),b)\)
which can be reduced to the already known formula
\(f(a,b) = \overline{f}(a)(b)\)
Our type based category seems to support exponentials obviously, because we can always construct them. Such a category is a cartesian closed category (CCC).
Details can be read in books on category theory. Now, first a sidestep follows - custom operators.
6. Operators
The idea is to contruct a new operator using the existing operator pair \(\lt\) - \(\gt\). This will only work if we use a capture object between.
So first we need a strategy object and than a the capture object:
namespace cat::op { const struct a_t {} a; const struct ta_t {} a; const struct fa_t {} a; const struct fta_t {} a; template<typename C, typename V> struct capture { V v; }; }
The \(\lt\) operator captures the function object v and also the capture strategy type - the type C. Beside the application operator I also want to provide transpose operators, which apply a value and returns the transpose of a function. Dependend on the capture strategy type the behaviour can be controlled:
namespace cat { template <typename F, typename O> decltype(auto) operator<(F&& f, const O&) { return op::capture<O,F>{fwd(f)}; } template<typename F, typename G> decltype(auto) operator>(F&& f, G&& g) { if constexpr (is_op<op::a_t,F>) { return fwd(f).v(fwd(g)); } if constexpr (is_op<op::ta_t,F>) { return ~fwd(f) <a> fwd(g); } if constexpr (is_op<op::fa_t,F>) { return functor<util::clear_type<G>,name::application>()(fwd(f).v)(fwd(g)); } if constexpr (is_op<op::fa_t,F>) { return functor<util::clear_type<G>,name::transpose()(fwd(f).v)(fwd(g)); } throw 1; } }
The operator strategy detection is implemented in the following way
namespace detail { template<typename A, typename C> struct is_op : std::false_type {}; template<typename A, typename X> struct is_op<A, op::capture<A,X>> : std::true_type {}; } template<typename A, typename C> static constexpr bool is_op = detail::is_op<A,util::clear_type<C>>::value;
The helper construction cleartype, which reduces the *value category" to a type expression is implemented this way
namespace cat::util { template<typename T> struct clear_type_decl { using T1 = typename std::remove_reference<T>::type; using T2 = typename std::remove_pointer<T1>::type; using type = typename std::remove_const<T2>::type; }; template<typename T> using clear_type = typename clear_type_decl<T>::type; }
Finally a test function shows how to use all of it
double test_list_functor(int i) { auto one_third = +[] (int e) { return e*0.33333; }; return one_third <a> i; }
The + sign generates a lambda into a fun<lambda> - see the introduction of the lambda function in the functions as interpretation section.
In the case of a binary function, we need the transpose of this function. If we provide the transpose generator as the operator ~, the example code could look like this
int test_list_functor(int a, int b) { auto multi = +[] (int e, int f) { return e*f; }; return ~multi <a> e <a> f; }
The transpose operator ~ returns a transpose function, which is defined as
namespace cat { namespace name { struct transpose {}; } template<typename F> struct fun<name::transpose,F> { fun(F&& _f, name::transpose) : f(fwd(_f)) {} template<typename X> constexpr decltype(auto) operator()(X&& x) { return +[ff=std::move(f),xx=fwd(x)](auto&&... y) mutable { return ff(xx,fwd(y)...); }; } F f; }; template<typename F> fun(F&&,transpose) -> fun<transpose,F>; }
With the transpose application operator we can save on operator call
int test_list_functor(int a, int b) { auto multi = +[] (int e, int f) { return e*f; }; return multi <ta> e <a> f; }
Every step of this evolution can be tested via the sourcecode from the git repo.
7. First Part Summary
Instead of writing loops we want to apply a function on the container elements
decltype(auto) my_fun() { auto f = [](int i) { return double(i/2); }; std::list l{1,2,3,4,5}; return f <fa> l; }
and get back a container of the result type of that function. This is what the concept of a functor means to be. But a functor isn't restricted to container types. Type encapsulation is the main aspect which can be handled in general by a functor.
For the practical application of functor operations, the availability of operators is important. The operator allows to plugin new functor definitions without changing the general usage via the operator.
Function application in the functor context is an extension of normal function application, which also can be expressed via an operator.
Beside values, function application may return the transpose of the function, where the applyed value is captured. The different application strategies can be chosen by appropriate operators.
The next goal is to develop the concept of polymorphic datatypes. Again the interpretation aspect plays the main role in this area.
8. Data as Interpretations
In an object oriented programming style to distinguish between functions and data makes not so much sense, because the struct or the class represents both. My position here is similar but not the same. Structs and classes stand for types and both functions and data are types. Because we can recognize a function by an interpreted fun template, we can do the same with data. Asking how functional languages are dealing with data, I give data structures the interpreter name ctr, which should be the shortcut for data constructor.
If we would say
struct circle { double r; };
without a very sophisticated analysis of the structure it would not be possible to identify this structure as data or as a function. So we can define now
namespace cat { template<typename T> struct ctr; namespace name { struct circle; } } using namespace cat; template<> struct ctr<name::circle> { double r; };
Now it's clear – it's data. Perhaps it makes sense at this point to introduce also a context
namespace cat { namespace name { struct shape; struct circle; } template<typename, typename> struct ctr; } using namespace cat; template<> struct ctr<name::shape,name::circle> { double r; };
This looks a little bit like inheritance - but only a little bit. We can now also use the name circle in different contexts
namespace cat { namespace name { struct grouping; } } using namespace cat; template<> struct ctr<name::grouping,name::circle> { std::list<std::string> names; };
The first application of these data structures may be a perimeter function
namespace cat::name { struct perimeter; } using namespace cat; template<> struct fun<name::perimeter> { double operator()(const ctr<name::circle>& c) { return 2 * pi * c.r; } double operator()(const ctr<name::rectangle>& r) { return 2 * (r.a + r.b); } };
Comparing this situation with pattern matching of constructors in functional languages we can also write
using namespace cat; template<> struct fun<name::perimeter> { template<typename T> double operator()(const ctr<name::shape,T>& t) { if constexpr (std::is_same<T,name::circle>::value) { return 2 * pi * t.r; } else if constexpr (std::is_same<T,name::rectangle>::value) { return 2 * (t.a + t.b); } else { std::runtime_error("Missing implementation"); } } };
At this point we can do a little bit more. We can associate a list of types to a context type and then we allow the construction of data types only for the defined typelist
namespace cat { template<typename... T> struct typelist; namespace name { struct rectangle; struct cuircle; struct shape { using types = typelist<circle,rectangle>; }; } }
Again I must be consequent. The structure shape should be a context
namespace cat { template<typename> struct ctx { using types = typelist<>; }; namespace name { struct shape; } } using namespace cat; template<> struct ctx<name::shape> { using types = typelist<name::circle,name::rectangle>; };
In the next step I want to check, if the data constructor type is valid. This means, that the data subtype must be in the typelist specification of the context.
namespace cat { template<typename C, typename D, typename = typename std::enable_if<is_element_of<C::types,D>::type> struct ctr; } using namespace cat; template<> struct ctr<ctx<name::shape>,name::circle> { double m_r; };
So, how does the iselementof looks like. Some insights into typelists are necessary.
9. Typelist
A typelist as any list has two fundamental parts - the first element
template<typename L> struct tl_first; template<typename T, typename... TT> struct tl_first<typelist<T,TT...>> { using type = T; };
and the tail
template<typename L> struct tl_tail; template<typename T, typename... TT> struct tl_tail<typelist<T,TT...>> { using type = typelist<TT...>; };
For the desired iselementof function let's first calculate the index of a type in the list – if available
template<typename T, typename L, std::size_t I = 0> struct tl_index_of; template<typename T, typename TT, typename... TTT, std::size_t I> struct fun<tl_index_of<T,typelist<TT,TTT...>, I>> { constexpr std::size_t operator*() { return std::is_same<T,TT>::value ? I : *fun<tl_index_of<T,typelist<TTT...>, I + 1>>(); } };
The call operator is here represented by the dereference operator, which works also if used with a template parameter.
If no match was found the empty list must be handled, here by setting the result to an exceptional value, which is the size of the typelist
template<typename T, std::size_t I> struct fun<tl_index_of<T,typelist<>, I>> { constexpr std::size_t operator*() { return I; } };
Now it's time to provide the tliselementof function, which translates the numeric index value into a boolean one.
template<typename T, typename L> struct tl_is_element_of; template<typename T, typename L> struct fun<tl_is_element_of<T,L>> { constexpr bool operator*() { return *fun<tl_size<L>>() > *fun<tl_index_of<T,L>(); } }
The quint essence of this work is an universal quantifier, which tells us, that for any type, which exists in the typelist of the context, a data constructor can be defined
template<typename T> using ctx_types = typename ctx<T>::types; #define TL_IS_ELEMENT_OF(A_C,A_T) \ fun<tl_is_element_of<A_T,ctx_types<A_C>>> #define UQ_CTX_TYPE(A_C,A_T) typename = \ typename std::enable_if<*TL_IS_ELEMENT_OF(A_C,A_T)()>::type
The data constructor definition looks now like this
template<typename C, typename T, UQ_CTX_TYPE(C,T)> struct ctr;
The introduction of the term universal quantifier as a property of a data constructor element is nice. Perhaps it is a good opportunity to make some simple notes on logic.
10. Sidestep Logic
What is logic? A very fundamental question. I'm not the person who should give a definition of logic here. But I know, that logic has to do with the underlying language. Within this language we describe first basic objects and then some construction principles, which describe how to construct more complex objects using the basic object. Because the more complex objects behave like the basic objects, we can apply the construction principles also to this more complex objects. This way a recursive language definition is developed.
First, the mathematicians started with a language, which was derived from a natural language like english. Then formal languages became of interest, like the lambda calculus or the combinator logic. Today we speak about homotopy type theory or quantitative type theory and perhaps there are other approaches.
The motivation behind the wish to use a formal language for logical purposes, is to construct proves by programs. Because logical proves may be very complex and thus difficult to manage by persons without a high risk of making mistakes.
Types semm to play an important role in such newer approaches to make logic. In our case a type is simply a name, which can be make known to the compiler. And the generic template engine of c++ allows to do things with these types. And these things have to do with logic. With types and their interpretations together with a framework, which describes the relation between these basic objects, we make logic or something similar to logic. But the logical aspect should becomme more and more important.
So this is a vague description of what we are doing here.
11. Polymorphic Types – Sumtype
Polymorphic datatypes are closely related to the concept of a sum in category theory. But let's first take a look on the idea of a product.
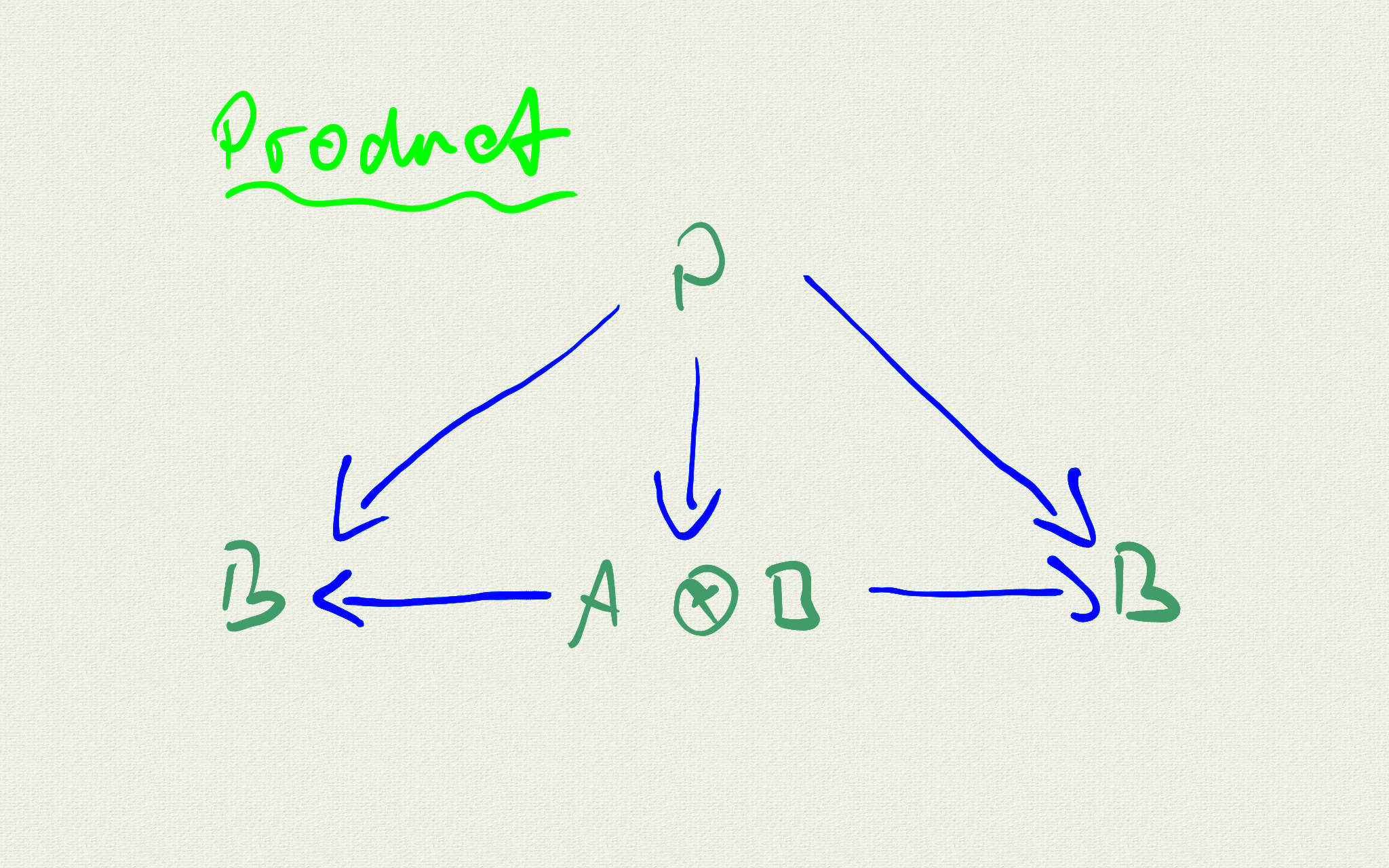
A product is related to other objects, which also have projections. An object P has perhaps the projections
\(P_a: P \rightarrow A \qquad \hat{=} \qquad A^P \\ P_b: P \rightarrow B \qquad \hat{=} \qquad B^P\)
Our product has the projections
\((A \otimes B)_a: (A \otimes B) \rightarrow A \qquad \hat{=} \qquad A^{A \otimes B} \\ (A \otimes B)_b: (A \otimes B) \rightarrow B \qquad \hat{=} \qquad B^{A \otimes B}\)
If we have many of such objects P, our product is characterized by the property, that every Pa can be written as
\(P_a = (A \otimes B)_a \circ C_p\)
where
\(C_p: P \rightarrow (A \otimes B) \qquad \hat{=} \qquad (A \otimes B)^P\)
So the idea of all this is to say, that a product is a best representiation of the conecpt of projections. Th is allows us to say, that a product is a limit, which means exactly - something very good.
Now let's go the opposite direction, by reversing the arrows.
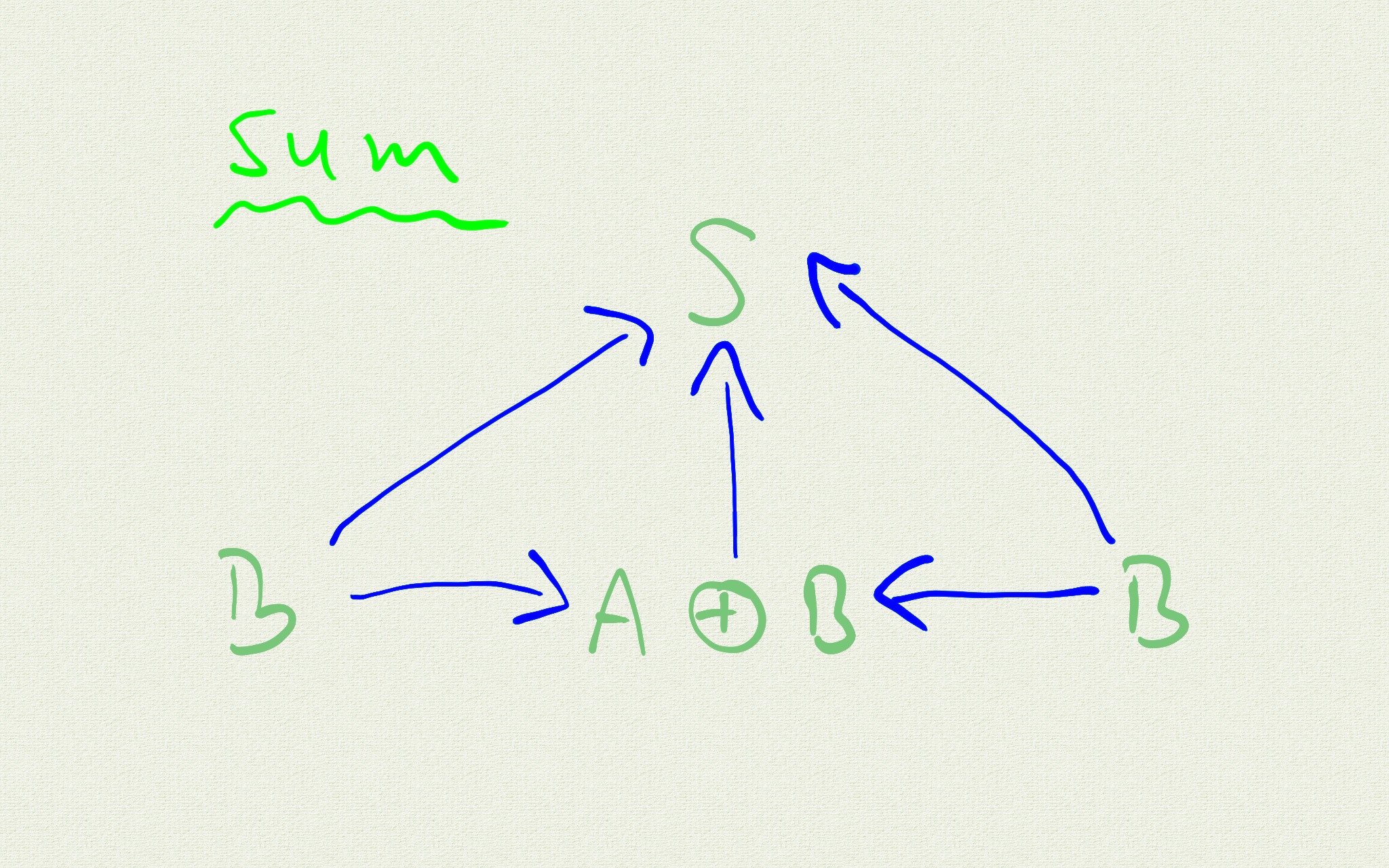
The opposite of an projection is an injection. Now we have two injections
\((A \oplus B)_a: A \rightarrow (A \oplus B) \qquad \hat{=} \qquad (A \oplus B)^A \\ (A \oplus B)_b: B \rightarrow (A \oplus B) \qquad \hat{=} \qquad (A \oplus B)^B\)
In analogy to the product every structure, which provides injections should be related to a sum via
\(I_a = C_s \circ (A \oplus B)_a\)
where
\(C_s: (A \oplus B) \rightarrow S \qquad \hat{=} \qquad S^{A \oplus B}\)
A sum is also called a coproduct because of the reverse arrow construction. As a coproduct, the limit property is also called colimit.
The main advantage of such a sum is that it represents many aspects by one aspect only. Comming back to the world of programming, such a common type is very useful as return type of a function. We can return a shape and this shape encapsulates perhaps a rectangle or a circle. We may automatically think on the object oriented programming feature inheritance. But I want to avoid the base class dependency. The base construction looks like
template<typename T> struct data { template<typename X> data(X&& x) : m_p(&x), m_i(tl_index_of<X,T>::value) {} template<typename F> decltype(auto) apply(F&& f) { return helper(fwd(f),T{},m_i); } template<typename F, typename L> decltype(auto) helper(F&& f, L l, std::size_t i) { if constexpr (std::is_same<L,typelist<>>::value) { throw 1; } else { if (i == 0) { auto p = static_cast<tl_first<L>*>(m_p) return f(p); } return helper(fwd(f),tl_tail<L>, i-1); } } void* m_p; const std::size_t m_i; };
The sum type is represented by a typelist. The constructor saves the index of the injected type into a member. With this index we can reconstruct the real type and are able to apply the real type to the polymorphic function.
A little bit of test code demonstrates the principle.
template<typename> struct obj { }; using objs = typelist<obj<circle>,obj<square>,obj<rectangle>>; struct print; template<> struct fun<print> { void operator()(obj<circle>*) { std::cout << "circle" << std::endl; } void operator()(obj<rectangle>*) { std::cout << "rectangle" << std::endl; } void operator()(obj<square>*) { std::cout << "square" << std::endl; } }; int main() { auto s = std::make_unique<obj<square>>(); data<objs> o(s.get()); o.apply(fun<print>()); auto c = ctr<shape,circle>{3.5}; return 0; }
The next step is to connect the polymorphic data structure with the data constructors ctr in a more flexibel fashion. From the coding perspective this all looks very similar to the structures we find in the visitor pattern area. This is the one and only place I mention this pattern.
So let's improve this initial example of a polymorphic data type. A very flexible approach is to create a data carrier class together with a base class
namespace base { struct carrier { carrier(std::size_t i) : index(i) {} const std::size_t index; }; } namespace detail { template<typename T> struct carrier : base::carrier { carrier(T&& _t) : base::carrier(ctr_index<clear_type<T>>), t(fwd(_t)) {} T t; }; }
Now let's align our first example
template<typename T, UQ_CTX(T)> struct data { template<typename X, UQ_CTX_CTR(T,X), UQ_CTX_COMPLETE(T)> data(X&& x) : c(new detail::carrier<X>{fwd(x)}) {} template<typename F> decltype(auto) apply(F&& f) const { return fwd(f) <op::d> *this; } template<typename F> decltype(auto) apply(F&& f) { return fwd(f) <op::d> *this; } std::unique_ptr<base::carrier> c; };
I anticipated the introduction of an application operator op::d and I added three universal qualifiers. First, the data type parameter should reference a context
#define UQ_CTX(A_T) typename = ctx_types<A_T>
Second, the constructor parameter should represent a data constructor stucture, which references to the same context as the data parameter
template<typename C, typename T> struct same_context : std::false_type {}; template<typename C, typename T> struct same_context<C,ctr<C,T>> : std::true_type {}; template<typename C, typename T> struct fun<same_context<C,T>> { constexpr bool operator*() { return same_context<C,T>::value; } }; #define UQ_CTX_CTR(A_T,A_X) typename = \ typename std::enable_if<*fun<same_context<A_T,A_X>>()>::type
The last qualifier checks if all contructor objects can be constructed
namespace detail { template<typename C, typename T> struct is_constructible; template<typename C, typename... T> struct is_constructible<C, typelist<T...>> { static constexpr bool value = (std::is_constructible<ctr<C,T>>::value && ...); }; } template<typename C> struct ctx_constructible { static constexpr bool value = detail::is_constructible<C,ctx_types<C>>::value; }; template<typename C> struct fun<ctx_constructible<C>> { constexpr bool operator*() { return ctx_constructible<C>::value; } }; #define UQ_CTX_COMPLETE(A_T) typename = \ typename std::enable_if<*fun<ctx_constructible<A_T>>()>::type
The cooresponding testcode is
int main() { data<shape> o(ctr<shape,circle>{1.0}); o.apply(fun<print>()); return 0; }
Bit isn't this polymorphic data type also a functor - better, can we deliver anfunctor interpretation for the function application?
12. Data as a Functor?
Indeed, we can simply align the list functor code to
template<typename T, typename F> struct fun<functor<data<T>>,F> { template<typename A> decltype(auto) operator()(A&& a) { return apply(fwd(a),ctx_types<T>{},fwd(a).c->index); } template<typename A, typename L> decltype(auto) apply(A&& a, L l, std::size_t i) { if constexpr (std::is_same<L,util::typelist<>>::value) { using LL = ctx_types<T>; auto pp = static_cast<carrier<ctr<T,util::tl_first<LL>>>*> (fwd(a).c.get()); using R = decltype(f(pp->t)); throw 1; return R(); } else { if (i == 0) { auto p = static_cast<carrier<ctr<T,util::tl_first<L>>>*> (fwd(a).c.get()); return f(p->t); } return apply(fwd(a), util::tl_tail<L>{}, i-1); } } F f; };
Now the test code looks like this
int main() { using namespace cat; data<shape> o(ctr<shape,circle>{1.0}); fun<print>() <op::f> o; return 0; }
This application works, but is it really functorial? The problem is the return value. The return value is not of the type data<void>. The function fun<print> should translate the type data<shape> to a datatype data<void>. But the return value is simply void. Another function could be fun<perimeter>. Then the return value should be data<double>, but we will get simply double as the return value.
Actually, we can say, that the application mechanism for the data objects is similar to functorial data, but not exactly the same. One measure to distinguish this situation from functorial data, could be to introduce a new operator. But what does it mean if the a functorial application changes the type containment structure. So a new operator is fine, but what is the structural meaning.
Technically, let's define a new operator
namespace op { const struct a_t {} a; const struct f_t {} f; const struct d_t {} d; template<typename C, typename V> struct capture { V v; }; }
The operator definitions must be aware of this type
template<typename F, typename G> decltype(auto) operator>(F&& f, G&& g) { if constexpr (is_op<op::a_t,F>) { return fwd(f).v(fwd(g)); } if constexpr (is_op<op::f_t,F>) { return functor<util::clear_type<G>>()(fwd(f).v)(fwd(g)); } if constexpr (is_op<op::nf_t,F>) { return data_application<util::clear_type<G>>()(fwd(f).v)(fwd(g)); } throw 1; }
Missing is the new concept dataapplication. Again, technically it's something like the functor concept
template<typename T> struct functor { template<typename F> constexpr decltype(auto) operator()(F&& f) const { return fun<functor<util::clear_type<T>>,F>{fwd(f)}; } }; template<typename T> struct data_application { template<typename F> constexpr decltype(auto) operator()(F&& f) const { return fun<data_application<util::clear_type<T>,F>{fwd(f)}; } };
The plugin code needs now only a new creation strategy
template<typename T, typename F> struct fun<data_application<data<T>>,F> { template<typename A> decltype(auto) operator()(A&& a) { return apply(fwd(a),ctx_types<T>{},fwd(a).c->index); } template<typename A, typename L> decltype(auto) apply(A&& a, L l, std::size_t i) { if constexpr (std::is_same<L,util::typelist<>>::value) { using LL = ctx_types<T>; auto pp = static_cast<carrier<ctr<T,util::tl_first<LL>>>*> (fwd(a).c.get()); using R = decltype(f(pp->t)); throw 1; return R(); } else { if (i == 0) { auto p = static_cast<carrier<ctr<T,util::tl_first<L>>>*> (fwd(a).c.get()); return f(p->t); } return apply(fwd(a), util::tl_tail<L>{}, i-1); } } F f; };
We can now apply a polymorphic function directly to the data object
auto data<shape> o(ctr<shape,circle>{2.2}); auto value = fun<perimeter>() <op::d> o;
With a small extension of the perimeter function
template<> struct fun<perimeter> { double operator()(const data<shape>& d) { return (*this) <op::d> d; } ... };
we can directly apply the function to the data
auto data<shape> o(ctr<shape,circle>{2.2}); auto value = fun<perimeter>() <op::a> o;
A further concept comes now, which is widely used in the area of operations with side effects. A operation may return something or nothing dependent on the behaviour of the technical behaviour of the environment. Of interest is especially the chaining of such operations.
13. The Monad
Monads are often mentioned in functional programming in the area of side-effect-ful operations. They are useful for it, but the meaning behind hasn't anything to do with side-effects. In the same sense a std::optional can be used to handle side-effects but that's not the nature of a std::optional. A std::optional may have one value or not. If it has a value, we can take this value as input for a function, which itself returns a std::optional - containing a value or not. In the context of operations with side effects this behaviour may be useful.
Containing a value or not is like a list, which can contain at most 1 element. So it is not a surprise, that there must exist a functor interpretation for a std::optional - only the capture helper must be implemented
template<typename T, typename F> struct fun<functor<std::optional<T>>,F> { template<typename A> decltype(auto) operator()(A&& a) { using type = decltype(f(std::declval<decltype(*a)>())); if constexpr (std::is_same<type,void>::value) { if (fwd(a)) { f(*fwd(a)); } } else { std::optional<type> ro; if (fwd(a)) { ro = f(*fwd(a)); } return ro; } } F f; };
In contrast to a normal functor situation, let's consider another function type:
\( f: A \rightarrow std::optional \langle B \rangle \)
If we take for \(A\) an \(int\) and for \(B\) a \(double\) the functor way would deliver
std::optional<std::optional<double>> test(std::optional<int> o, std::function<std::optional<double>(int)> f) { std::optional<std::optional<double>> r; if (o) { r = f(*o); } return r; }
The functor operation would return an std::optional<std::optional<double>>. It's clear, a std::optional<double> would carry enough information. But before we start now to implement a sophisticated template deduction algorithm, to solve this problem, it's worth to show, that the nested std::optional construction represents a binary product. This is a nice example, which tells something about abstraction in category theory. Let's take a look on the following pattern sequence
\( optional \langle optional \langle int \rangle \rangle \qquad \hat{=} \qquad optional(optional(int)) \)
Here I'm replacing angle brackets by round brackets. Now it looks now like a composition
\( optional(optional(int)) \qquad \hat{=} \qquad (optional \circ optional)(int) \)
And as a shortcut we can write
\( (optional \circ optional)(int) \qquad \hat{=} \qquad optional^2(int) \)
Now take a look on a list and a optional or more in general on a G and on a H
\( G \circ H \)
Next we can define the projections
\( first(G \circ H) = G \)
and
\( second(G \circ H) = H \)
Because of the projections we can say \( G \circ H \) is a binary product. But the \(\circ\) is perhaps distracting. We can also write
\( (G,H) \qquad \hat{=} \qquad G(H(type)) \qquad \hat{=} \qquad G \langle H \langle type \rangle \rangle \)
Now let's again consider the composition of the identical type constructors or type functions
\( G \circ G \)
The question is now, if there exists an operation \(\mu\), which holds
\( \mu: G \circ G \rightarrow G \)
Such a μ we can find on values very often
\( (string, string) \rightarrow string \)
is just a string concatenation and
\( (int,int) \rightarrow int \)
can be expressed by an addition or a multiplication.
The μ is the essence of a structure, which is called a monoid.
In the case, such a μ exists for type constructors or type functions like an optional or a list, we can define the monadic binding
\( G \langle A \rangle \rightarrow ( A \rightarrow G \langle B \rangle ) \rightarrow G \langle B \rangle \)
Such a G can be regarded as a monad, which itself can be regarded in a certain context as a monoid.
From the programmer perspective the task is now to deliver a new operator and the monadic binding. For the structurs optional and list we have already functor interpretations. For both structures also an interpretation of a monad is possible.
14. The Monad Code
The monad interpretation looks identical compared to the functor one
template<typename T> struct functor { template<typename F> constexpr decltype(auto) operator()(F&& f) const { return fun<functor<util::clear_type<T>>,F>{fwd(f)}; } }; template<typename T> struct monad { template<typename F> constexpr decltype(auto) operator()(F&& f) const { return fun<monad<util::clear_type<T>>,F>{fwd(f)}; } };
Next we can introduce a monadic operator type
namespace op { const struct a_t {} a; const struct f_t {} a; const struct m_t {} m; template<typename C, typename V> struct capture { V v; }; }
The closing part of the operator can now be written as
template<typename F, typename G> decltype(auto) operator>(F&& f, G&& g) { if constexpr (is_op<op::a_t,F>) { return fwd(f).v(fwd(g)); } if constexpr (is_op<op::f_t,F>) { return functor<util::clear_type<G>>()(fwd(f).v)(fwd(g)); } if constexpr (is_op<op::m_t,F>) { return monad<util::clear_type<G>>()(fwd(f).v)(fwd(g)); } throw 1; }
An example for a monad function can be that of an optional
template<typename T, typename F> struct fun<monad<std::optional<T>>,F> { template<typename A> decltype(auto) operator()(A&& a) { using type = decltype(f(std::declval<decltype(*a)>())); if constexpr (std::is_same<type,void>::value) { if (fwd(a)) { f(*fwd(a)); } } else { type ro; if (fwd(a)) { ro = f(*fwd(a)); } return ro; } } F f; };
A test for this monad could be
std::optional<double> test_optional_functor(std::optional<int> o) { auto one_third = [] (int e) { return std::optional<double>(e*0.33333); }; using namespace cat; using namespace cat::op; return one_third <<m>> o; } int main() { auto o = test_optional_functor({1}); if (o) { std::cout << *o << std::endl; } return 0; }
This situation describes a monadic application, where a monadic function is applied to a monadic value. A monadic binding goes the opposite direction, which takes a monadic value and binds it to a monadic function. This can be achieved simply by switching the parameters around. The monadic binding is often used to simulate the procedural left to right sequencing of commands. Here the actual functor code motivates the go first the analog application way.
Another problem we have still regarding the use of operators. We don't have control over the operator precedence. A right to the left logic is easier to implement, than a left to right sequencing.
15. Currying
Actually we can apply a function on a value
fun<x>() <op::a> v;
But what can we do if the function has more than one parameter in it's definition. We should be able to write the following
f<x>() <op::a> v1 <op::a> v2;
To deliver such a functionality let's first introduce a new operator
namespace cat::op { struct t_t t; }
Now we can plugin a new concept - the function transpose - according to the considerations in an earlier section. A function transpose is perhaps not the same as a curried function, because the transposed function is not equal compared to the original one - in c++.
The transpose of a function is again a function, where values are captured. Again, the term capture of a lambda is equivalent to members of an object. So a transpose function could be
struct transpose {}; template<typename F, typename A> struct fun<transpose, F ,A> { fun(F&& _f, A&& _a, transpose) : f(fwd(_f)), a(fwd(_a)) {} template<typename... X> constexpr decltype(auto) operator()(X&&... x) { return f(a,fwd(x)...); } F f; A a; }; template<typename F, typename A> fun(F&&,A&&,transpose) -> fun<transpose,F,A>;
The operator handler can now return this function in the following way
template<typename F, typename G> decltype(auto) operator>(F&& f, G&& g) { if constexpr (is_op<op::a_t,F>) { return fwd(f).v(fwd(g)); } if constexpr (is_op<op::t_t,F>) { return fun(fwd(f).v,fwd(g),transpose{}); } if constexpr (is_op<op::f_t,F>) { return functor<util::clear_type<G>>()(fwd(f).v)(fwd(g)); } if constexpr (is_op<op::d_t,F>) { return data_application<util::clear_type<G>>()(fwd(f).v)(fwd(g)); } if constexpr (is_op<op::m_t,F>) { return monad<util::clear_type<G>>()(fwd(f).v)(fwd(g)); } throw 1; }
A test code could loo like this
int test_transpose_1() { auto multi = [] (int e, int f) { return e*f; }; using namespace cat; return multi <op::t> 6 <op::a> 2; } int test_transpose_2() { auto multi = [] (int e, int f) { return e*f; }; using namespace cat; return (multi <op::t> 6 <op::t> 2)(); } int main() { auto r1 = test_transpose_1(); std::cout << r1 << std::endl; auto r2 = test_transpose_2(); std::cout << r2 << std::endl; return 0; }
The fact, that we have now two operators to express a function application may create the wish to reduce these operators to one. Espacially if we regard a functor operation, where we apply a binary function on a list of values. The result will be a list of unary functions, which we want apply again to a list of values. This consideration leads to the concept of an applicative. This concept lies between the functor and the monad. So an applicative is a functor but not a monad. A monad is an applicative.
16. Applicative
Comming soon …
17. Code Examples
The example code can be found at http://git.macajobe.de.
For making a runnable program take a look at the README.
18. Mathematics vs. Programming
There is certainly a big community, which is very impressed by the topic programming. Even it should be possible to learn children how to write or create software – is the opinion. Why there isn't an equivalent community, which states, that children should learn mathematics (perhaps there is one I don't know)? Programming seems to be much simpler, could be an answer. Or, programming is much more exiting?
In the same direction goes the evolution of getting more and more programming languages. It seems, there are many problems, which can only be solved by programming.
Another aspect is the device – the computer, the smartphone – which seems to be an object of desire and the language to talk with are programming languages.
If I talk in this way about programming, the feeling must arise, that something is missing. The question is "why".
One direct answer on my own question "why" is, that programmiing let us feel to make important things, because we are using a language in a formalized, systemtic way, which give us the impression it has to do with logic. So we feel like mathematicians.
Indeed, there is a connection between programming and logic. But in the end our feeling is in general wrong.
But what are the indicators of this failure. I think it is expressed in the yearning after new programming languages, new language features and new language concepts. Even I am a highly experienced c++ developer – and I can say it's a complex language – not so easy to manage – what is the result of my logical work. What is the logic of my matheamical work my soul feels to do.
Devices are all around. So children will become good pyhsicists, because of the experiences they make in the area if doing something and analyzing the response. In the same way software developers are making code and they only know if it is working correctly by testing. Without testing we cannot be sure.
But logic in a mathematical sense is more art then physics. And art must be exchanged by people and certainly not by devices.
Mathematics is only one element in the world of the art of thinking systematically. Philosophy and Linguistic as scientific research areas are in the same way important. So if you are bored - take a look on these disciplines in the area of logic.
If we would argue, can we really distinguish devices from human beeings and is my last statement really acceptable I would say.
We are able to construct a world where it will be difficult to distinguish devices from a human beeings but we can also do the opposite.
In a world in which it is difficult to know if an intelligence is of human nature or not, it should be alway possible to identify the origin of an intelligence, because of the creation path - something like a birth certificate. I ignore my personal fellings at this point. That's a different thing.
Now, is it possible, that a human beeing can construct a device, which is more intelligence than a human beeing. Because the term intelligence is not a very clear term - the meaning is not totally clear - we can be more precise.
Is it possible, that a human beeing can construct a device, which has more capabilities in logic than the creator?
But if there is an intelligence of an higher order, it would not be possible for human beeings to prove, that this is really the case. This means that this intelligence is potentially bullshit. I cannot prove that something is correct but I don't understand it.
So what is the motivation to find such an intelligence. It's a way to introduce god. And there is no way to dicuss about god. On one hand god is dead, so take the new one.
19. References
- https://gist.github.com/sorrge/2d2271e57ad1e91a50ea Dependent types in C++
- https://web.mit.edu/6.001/6.037/sicp.pdf Structure and Interpretation of Computer Programs
- https://vittorioromeo.info/index/blog/capturing_perfectly_forwarded_objects_in_lambdas.html